- Типы данных (столбцов, колонок переменных) MySQL.. Диапазоны хранимых значений — подробное, понятное описание. Чем отличаются
- Primary tabs
- Forums:
- Целые числа
- Вещественные числа
- Строки — строковый тип данных
- Бинарные данные (BLOB)
- Дата и время
- Перечисления(ENUM)
- Множества(SET)
- Как получить список и описание всех колонок в таблице Microsoft SQL Server?
- Получаем список колонок таблицы с помощью представления информационной схемы
- Получаем список столбцов таблицы с помощью системного представления sys.columns
- Получаем список колонок таблицы с помощью системной процедуры sp_columns
- Колоночные СУБД — принцип действия, преимущества и область применения
Типы данных (столбцов, колонок переменных) MySQL.. Диапазоны хранимых значений — подробное, понятное описание. Чем отличаются
Primary tabs

Forums:
Иваньчева Т. А. Методическое пособие по языку SQL:
Тип данных задает множество правильных значений переменной и множество операций, которые над ней можно выполнять.
Например, над числами разрешены все арифметические операции, над строками эти операции не имеют смысла. Каждый столбец таблицы определяется на своем типе, исходя из тех данных,
которые предполагается хранить в этом столбце.
СУБД MySQL обеспечивает следующие типы данных:
Целые числа
| Тип | Возм. опции | Хранимый объём | Диапазон |
|---|---|---|---|
| TINYINT | [(length)] [UNSIGNED] [ZEROFILL] | 1 байт | Диапазон числа со знаком от –128 до 127. Диапазон числа без знака (unsigned) от 0 до 255. |
| SMALLINT | [(length)] [UNSIGNED] [ZEROFILL] | 2 байт | Диапазон числа со знаком от –32768 до 32767. Диапазон числа без знака (unsigned) от 0 до 65535. |
| MEDIUMINT | [(length)] [UNSIGNED] [ZEROFILL] | 3 байт | Диапазон числа со знаком от –8388608 до 8388607. Диапазон числа без знака (unsigned) от 0 до 16777215. |
| INT (или INTEGER) | [(length)] [UNSIGNED] [ZEROFILL] | 4 байт | Диапазон числа со знаком от –2147483648 до 2147483647. Диапазон числа без знака (unsigned) от 0 до 4294967295. |
| BIGINT | [(length)] [UNSIGNED] [ZEROFILL] | 8 байт | Диапазон числа со знаком от –9223372036854775808 до 9223372036854775807. Диапазон числа без знака (unsigned) от 0 до 18446744073709551615. |
- Длина поля length определяет, сколько всего цифр может иметь число при его отображении.
По факту не определяет объём выделяемой памяти, и может вообще игнорировать выводящей программой. Используется, например вместе с ZEROFILL, например:
значение 5 превращается в «00005».
Вещественные числа
Вещественные или дробные числа в общем виде записываются так:
Где length – количество знакомест(ширина поля), в которых
будет размещено дробное число, dec – количество знаков после
точки.
- FLOAT [(значение_точности)] — Число с плавающей запятой. FLOAT(4) и FLOAT одиночная точность. FLOAT(8) обеспечивает двойную точность.
- FLOAT [(length,dec)] — Число одиночной точности с мак-симальной длиной и фиксированным числом десятичных чисел (4 байта).
- DOUBLE — Число с плавающей запятой, обеспечивает двойную точность.
- REAL — Синоним для DOUBLE
- DECIMAL — Дробное число, хранящееся в виде строки
– вещественное число, состоящее из 9 цифр и имеющее 2 цифры после точки.
Строки — строковый тип данных
- CHAR(NUM) — Строки фиксированной длины 65 535 символов
- VARCHAR(NUM) — Строка переменной длины 65 535 символов
- TINYTEXT — Может хранить максимум 255 символов
- TEXT — Может хранить максимум 65 535 символов
- MEDIUMTEXT — Может хранить максимум 16 777 215
- LONGTEXT — Может хранить максимум 4 294 967 295 символов
Строковый тип данных позволяет хранить текстовую информацию.
Где NUM при определении типа означает длину строки. Чаще всего применяется тип TEXT.
Обычно при поиске по текстовым полям по запросу SELECT не берется в рассмотрение регистр символов, т.е. строки «ФЕДЯ» и «Федя» считаются
одинаковыми.
Однако если указан флаг BINARY, то при запросе SELECT строка будет сравниваться с учетом регистра.
Например:
Строка может заключаться либо в одинарные кавычки ( ‘) либо в двойные кавычки ( « ).
Примеры правильных строк:
Апострофы, если они используются внутри строки, удваиваются.
Бинарные данные (BLOB)
- TINYBLOB — Двоичный объект с максимальной длиной 255 байт.
- BLOB — Двоичный объект (максимальная длина 65535 байт)
- MEDIUMBLOB — Двоичный объект с максимальной длиной 16777216 байт.
- LONGBLOB — Двоичный объект с максимальной длиной 232 байт.
Тип данных BLOB (Binary Large Object) используется для хранения рисунков, фотографий, графиков и других двоичных объектов в базе данных.
Дата и время
- DATE — 3 байт — Дата в формате ГГГГ-ММ-ДД
- TIME — 3 байт — Время в формате ЧЧ:ММ:СС
- DATETIME — 8 байт — Дата и время в формате ГГГГ-ММ-ДД ЧЧ:ММ:СС
- TIMESTAMP — 4 байт — Дата и время в формате Unix timestamp. Однако при получении значения поля оно отображается не в формате timestamp, а в виде ГГГГММДДЧЧММСС, что сильно умаляет преимущества его использования в PHP.
- YEAR[(M)] — 1 байт — От 1901 до 2155 для YEAR(4) От 1970 до 2069 для YEAR(2)
Этот тип данных используется для хранения данных о дате и времени.
Столбцы YEAR предназначены для хранения только года, указание параметра M позволяет задать формат года.
Так, для YEAR(2) год представляется в виде двух цифр, например 05 или 97, с диапазоном данных от 1970 до 2069.
А тип YEAR(4) позволяет задать тип в виде 4 цифр YYYY, например 2005 или 1997, с диапазоном от 1901 до 2155 года. Если параметр не указан, то по умолчанию он считается равным 4.
Надо заметить, что в некоторых случаях в PHP будет проще самостоятельно генерировать дату и время при вставке данных в таблицу, а не задействовать встроенные в MySQL типы.
Перечисления(ENUM)
При использовании этого типа данных значением столбца может быть только одно значение из заданного списка. Примеры:
Определение столбца задано так:
— здесь
столбец с именем hide (т.к. его имя совпадает с ключевым словом, поэтому имя взято в обратные кавычки) может иметь только одно значение из заданного списка ‘show’,’hide’. Значением по умолчанию для этого столбца является значение ‘show’.
Множества(SET)
Значением столбца может быть одно или несколько значений из заданного списка. Например, поле f1 определено следующим образом:
Источник
Как получить список и описание всех колонок в таблице Microsoft SQL Server?
В данной заметке будет рассмотрено несколько способов получения информации о столбцах таблицы в базе данных Microsoft SQL Server, например, мы научимся получать список колонок таблицы, включая их тип данных, с помощью SQL запроса.

Начну с того, что если Вам нужно просто визуально посмотреть, какие колонки или какой тип данных у той или иной колонке в таблице, то Вы для этого можете использовать графический функционал SQL Server Management Studio, а именно «Обозреватель объектов». Например, для того чтобы посмотреть информацию о столбцах таблицы, необходимо плюсиком открыть соответствующий контейнер.
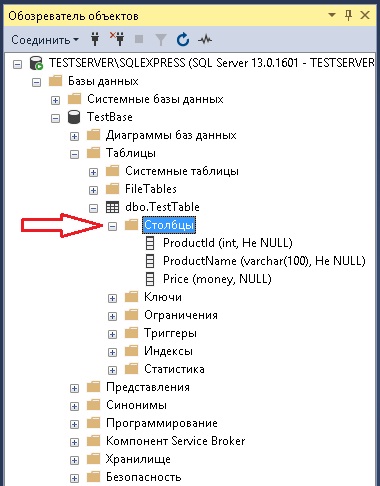
Но если Вам необходимо выгрузить эту информацию или обработать ее в SQL инструкции, то в этом случае необходимо обращаться к системным объектам SQL Server с помощью языка SQL, как и к каким именно объектам обращаться мы сейчас и рассмотрим.
Примечание! Все примеры ниже мы будем рассматривать в Microsoft SQL Server 2016 Express. В базе данных создана тестовая таблица TestTable, она имеет всего три столбца.
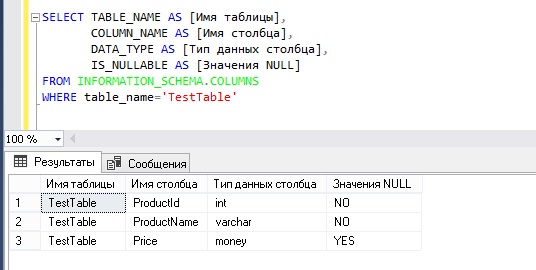
Получаем список колонок таблицы с помощью представления информационной схемы
В Microsoft SQL Server существует специальная схема — INFORMATION_SCHEMA, которая содержит метаданные для всех объектов базы данных. В данной схеме есть представление COLUMNS, с помощью которого и можно получить информацию о колонках таблицы. Также в ней есть и другие полезные представления, о которых мы разговаривали в статье — «Представления информационной схемы Microsoft SQL Server».
А теперь допустим, нам нужно получить информацию о столбцах в таблице, например, имя столбца, тип данных и возможность принятия значения NULL, для этого мы напишем следующий запрос, в котором обратимся к представлению COLUMNS информационной схемы.
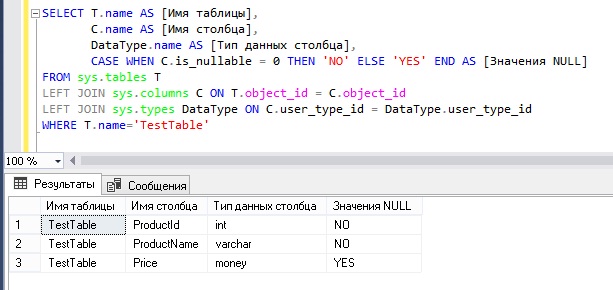
Получаем список столбцов таблицы с помощью системного представления sys.columns
Также информацию о колонках таблицы можно получить с помощью системного представления sys.columns, но только в этом случае для получения точно такого же результата, как был выше, необходимо будет объединять несколько системных представлений, а именно sys.tables, sys.columns и sys.types, так как в представлении sys.columns есть только идентификаторы нужных нам данных.
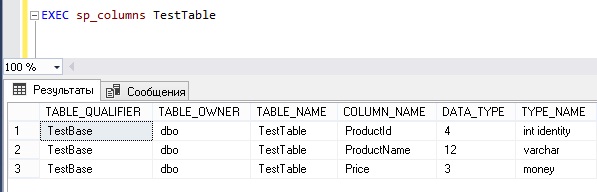
Получаем список колонок таблицы с помощью системной процедуры sp_columns
В SQL Server существует специальная системная процедура sp_columns, которая как раз и предназначена для получения информации о колонках таблицы.
Какой из рассмотренных выше способов Вам подойдет и окажется удобней решать Вам, а у меня на этом все, удачи!
Заметка! Новичкам рекомендую посмотреть мой видеокурс по T-SQL для начинающих, с помощью него Вы «с нуля» научитесь работать с SQL и программировать на T-SQL.
Источник
Колоночные СУБД — принцип действия, преимущества и область применения
Середина 2000-х годов ознаменовалась бурным ростом числа колоночных СУБД. Vertica, ParAccel, Kognito, Infobright, SAND и другие пополнили клуб колоночных СУБД и разбавили гордое одиночество Sybase IQ, основавшей его в 90х годах. В этой статье я расскажу о причинах популярности идеи по-колоночного хранения данных, принцип действия и область использования колоночных СУБД.
Начнем с того, что популярные в наше время реляционные СУБД — Oracle, SQL Server, MySQL, DB2, Postgre и др. базируются на архитектуре, отсчитывающей свою историю еще c 1970-х годов, когда радиоприемники были транзисторными, бакенбарды длинными, брюки расклешенными, а в мире СУБД преобладали иерархические и сетевые системы управления данными. Главная задача баз данных тогда заключалась в том, чтобы поддержать начавшийся в 1960-х годах массовый переход от бумажного учета хозяйственной деятельности к компьютерному. Огромное количество информации из бумажных документов переносилось в БД учетных систем, которые должны были надежно хранить все входящие сведения и, при необходимости, быстро находить их. Такие требования обусловили архитектурные особенности реляционных СУБД, оставшиеся до настоящего времени практически неизменными: построчное хранение данных, индексирование записей и журналирование операций.
Под построчным хранением данных обычно понимается физическое хранение всей строки таблицы в виде одной записи, в которой поля идут последовательно одно за другим, а за последним полем записи в общем случае идет первое следующей записи. Приблизительно так:
[A1, B1, C1], [A2, B2, C2], [A3, B3, C3]…
где A, B и С — это поля (столбцы), а 1,2 и 3 — номер записи (строки).
Такое хранение чрезвычайно удобно для частых операций добавления новых строк в базу данных, хранящуюся как правило на жестком диске – ведь в этом случае новая запись может быть добавлена целиком всего за один проход головки накопителя. Существенные ограничения по скорости, накладываемые НМЖД, вызвали также необходимость ведения специальных индексов, которые позволяли бы отыскивать нужную запись на диске за минимальное количество проходов головки HDD. Обычно формируется несколько индексов, в зависимости от того, по каким полям требуется делать поиск, что увеличивает объем БД на диске иногда в несколько раз. Для отказойустойчивости, традиционные СУБД автоматически дублируют операции в логах, что приводит к еще большему месту занимаемому на дисках. В итоге, например среднестатистическая БД Oracle занимает на диске в 5 раз больше места, чем объем полезных данных в ней. Для среднепотолочной БД на DB2 это отношение еще больше — 7:1.
Однако в 1990-х, с распространением аналитических информационных систем и хранилищ данных, применявшихся для управленческого анализа накопленных в учетных системах сведений, стало понятно, что характер нагрузки в этих двух видах систем радикально отличается.
Если транзакционным приложениям свойственны очень частые мелкие операции добавления или изменения одной или нескольких записей (insert/update), то в случае аналитических систем картина прямо противоположная – наибольшая нагрузка создается сравнительно редкими, но тяжелыми выборками (select) сотен тысяч и миллионов записей, часто с группировками и расчетом итоговых значений (так называемых агрегатов). Количество операций записи при этом невысоко, нередко менее 1% общего числа. Причем часто запись идет крупными блоками (bulk load). Отметим, что у аналитических выборок есть одна важная особенность – как правило, они содержат всего несколько полей. В среднем, в аналитическом SQL-запросе пользователя их редко бывает больше 7–8. Это объясняется тем, что человеческий разум не в состоянии нормально воспринимать информацию больше чем в 5–7 разрезах.
Однако что произойдет, если выбрать, например, только 3 поля из таблицы, в которой их всего 50? В силу построчного хранения данных в традиционных СУБД (необходимого, как мы помним, для частых операций добавления новых записей в учетных системах) будут прочитаны абсолютно все строки целиком со всеми полями. Это значит, что не важно, нужны ли нам только 3 поля или 50, с диска в любом случае они все будут прочитаны целиком и полностью, пропущены через контроллер дискового ввода-вывода и переданы процессору, который уже отберет только необходимые для запроса. К сожалению, каналы дискового ввода-вывода обычно являются основным ограничителем производительности аналитических систем. Как результат, эффективность традиционной СУБД при выполнении данного запроса может снизиться в 10–15 раз из-за неминуемого чтения лишних данных. Причем действие закона Мура на скорость ввода-вывода дисковых накопителей куда слабее, чем на скорость процессоров и объемы памяти. Так что, видимо, дальше ситуация будет только усугубляться.
Решить эту проблему призваны колоночные СУБД. Основная идея колоночных СУБД — это хранение данных не по строкам, как это делают традиционные СУБД, а по колонкам. Это означает, что с точки зрения SQL-клиента данные представлены как обычно в виде таблиц, но физически эти таблицы являются совокупностью колонок, каждая из которых по сути представляет собой таблицу из одного поля. При этом физически на диске значения одного поля хранятся последовательно друг за другом — приблизительно так:
[A1, A2, A3], [B1, B2, B3], [C1, C2, C3] и т.д.
Такая организация данных приводит к тому, что при выполнении select в котором фигурируют только 3 поля из 50 полей таблицы, с диска физически будут прочитаны только 3 колонки. Это означает что нагрузка на канал ввода-вывода будет приблизительно в 50/3=17 раз меньше чем при выполнении такого же запроса в традиционной СУБД. 
Кроме того, при поколоночном хранении данных появляется замечательная возможность сильно компрессировать данные, так как в одной колонке таблицы данные как правило однотипные, чего не скажешь о строке. Алгоритмы компрессии могут быть разные. Приведем пример одного из них — так называемого Run-Length Encoding (RLE):
Если у нас есть таблица со 100 млн записей, сделанных в течение одного года, то в колонке «Дата» на самом деле будет храниться не более 366 возможных значений, так как в году не более 366 дней (включая високосные года). Поэтому мы можем 100 млн отсортированных значений в этом поле заменить на 366 пар значений вида и хранить их на диске в таком виде. При этом они будут занимать приблизительно в 100 тыс. раз меньше места, что также способствует повышению скорости выполнения запросов.
С точки зрения разработчика, колоночные СУБД как правило соответствуют ACID и поддерживают в значительной степени стандарт SQL-99.
Колоночные СУБД призваны решить проблему неэффективной работы традиционных СУБД в аналитических системах и системах в подавляющим большинством операций типа «чтение». Они позволяют на более дешевом и маломощном оборудовании получить прирост скорости выполнения запросов в 5, 10 и иногда даже в 100 раз, при этом, благодаря компрессии, данные будут занимать на диске в 5-10 раз меньше, чем в случае с традиционными СУБД.
У колоночных СУБД есть и недостатки — они медленно работают на запись, не подходят для транзакционных систем и как правило, ввиду «молодости» имеют ряд ограничений для разработчика, привыкшего к развитым традиционным СУБД.
Колоночные СУБД применяются как правило в аналитических системах класса business intelligence (ROLAP) и аналитических хранилищах данных (data warehouses). Причем объемы данных могут быть достаточно большими — есть примеры по 300-500ТБ и даже случаи с >1ПБ данных.
Ссылки для дальнейшего чтения:
[1] Перевод статьи М. Стоунбрекера ««One Size Fits All»: An Idea Whose Time Has Come and Gone»— citforum.ru/database/articles/one_size_fits_all
[2] История о том как Zynga использует Vertica для реал-таймовой игровой платформы. С ней можно познакомиться по этой ссылке — tdwi.org/blogs/wayne-eckerson/2010/02/zynga.aspx
[3] Единственный мне известный Open Source вариант коммерческой колоночной СУБД — InfoBright Community Edition www.infobright.org
По наводке Олега Цибульняка:
[4] LucidDB — Изначально оpensource-ная колоночная СУБД. Позиционируется как замена MySQL для аналитических задач www.luciddb.org
PS. Если есть еще интересные материалы о колоночных СУБД — давайте ссылки, вставлю в текст.
Источник