- MySQL JSON columns and virtual indexes
- Гибкая схема хранения данных в MySQL (JSON)
- Предыстория
- Как мы записываем данные в MySQL
- Хранение данных в MySQL
- Хранение данных в MySQL: key/value
- Хранение данных в MySQL: JSON
- Document store
- Хранение данных в MySQL: JSON + индексы
- Шаг 1. Создание виртуальной колонки
- Шаг 2. Создание индекса
- New in MySQL 8.0
- descending/ascending
- Вывод результатов
- Полнотекстовый поиск внутри документов JSON
- Not only IoT
MySQL JSON columns and virtual indexes

Problem — Here at 1mg, we use MySQL where we came across the task to store patient symptoms in JSON for easy access and retrieval. We needed to store multiple symptoms already present in the database along with comments in case of other symptoms.
The major issue was storing this without creating another column for comments which will in this case have remained null for most of the entries.
To solve this problem we found a unique method called virtual columns which, can extract data from the JSON values and can be used to index them.
The solution can be visualized below.

The base for the solution:
- Upgrade the MySQL from our current version 5.6 to minimal version 5.7.8 that supports JSON.
- Migrate the data from the old MySQL to the new one.
- See nothing breaks in the process. (Rails gem update in our case)
The 1mg DevOps team handled the data migration and up-gradation of the MySQL database on AWS pretty well. While the database up-gradation was going, we parallelly started implementing JSON datatype in the development environment. We found a few important pieces of information about JSON handling and storage limits which are described below.
The references to what I will be writing here can be found in the MySQL bible.
Part 1 — MySQL JSON support
MySQL started supporting the native JSON data type defined by RFC 7159 that enables efficient access to data in JSON from version 5.7.8. So if you have an upgraded version of MySQL you can refer to this guide to do so.
Earlier MySQL provided support for storing JSON encoded stings but having JSON support in the database gives a few advantages over storing JSON encoded strings.
- Automatic Validation of the JSON data.
- Optimized Storage.
The space required to store the MySQL JSON type is the same as LONGTEXT or LONGBLOB type. This in fact depends upon the max_allowed_packet system variable. Which defaults to the 4MB and can be extended up to 1GB.
So many of you will know what JSON data types are. But here is a small recap of this.

JSON stands for ( JavaScript Object Notation)
It was developed as a lightweight format for storing and transporting data.
There are two types of JSON values:-
- JSON array:- A JSON array contains a list of values separated by commas and enclosed within [ and ] characters.
Eg. [“abc”, 10, null, true, false] - JSON Object:- A JSON object contains a set of key-value pairs separated by commas and enclosed within < and >characters.
Eg.
Let’s start with instructions to implement JSON columns in MySQL.
- First, start MySQL 5.7.8 or above. (this is a crucial step don’t skip this).
- Create a new DB to test this. (If you want to ruin your current DB skip this step.)
- Create a new table by writing the following commands.
4. Insert values in the table
Here is an explanation of what happened above.
We are inserting values in the above-created (step3) of the table i.e. “table1”. “table 1” has a column “jdoc” of type JSON. In step 4 we inserted a JSON object <“key1”: “value1”, “key2”: “value2”>in the table. A question arises why we have included the JSON object in single quotes(‘’)? Well, this is due to the reason that MySQL only supports inserting strings. MySQL matches the syntax of the string with the data type of the field and parses JSON from it accordingly.
6. Check that the values inserted from above are in the correct format.
This will return the data in the following format
This looks like it’s working.
KUDOS! we have finished our first step in implementing JSON columns in the MySQL database table.
Part 2 — Extracting values from fields.
Now came the second part extracting the values which we have added in the above exercise.
JSON_EXTRACT method is used to extract the data from the JSON fields.
As per the official documents of MySQL method is declared as follows
This method returns data from the JSON document, selected from the parts of the document matched by the path arguments. Returns NULL if any argument is NULL or no paths locate a value in the document. An error occurs if the json_doc argument is not a valid JSON document or any path argument is not a valid path expression.
The return value consists of all values matched by the path arguments. If it is possible that those arguments could return multiple values, the matched values are autowrapped as an array, in the order corresponding to the paths that produced them. Otherwise, the return value is the single matched value.
MySQL supports the -> operator as shorthand for this function as used with 2 arguments where the left-hand side is a JSON column identifier (not an expression) and the right-hand side is the JSON path to be matched within the column.
Let’s start with instructions on how to extract MySQL data from the JSON.
- We will be using the same table as above for this.
- Clear the table using the following command
3. Add the following values to the table using the given command
4. This will give the following table schema
5. Now if you want to perform operations on the table you can extract and order data from the following commands
6. This will return the following values from the table.
7. Check the explanation given below.
Here is an explanation.
The command given in point 5 gives a crude idea of how to extract data from the rows and order them. Here we are finding all the rows with id > 1. By first extracting id from the JSON and comparing it with the greater than condition and then ordering the data extracted from the table on basis of name.
Part 3 — Indexing the JSON values
This one is a tricky part. MySQL doesn’t support indexing the JSON values. To support this, developers have found a turnaround by using the MySQL feature of virtual columns. You may be thinking about what are virtual columns here is the explanation.
What are virtual columns?
MySQL 5.7 introduced a new feature called virtual/generated column. It is called generated column because the data of this column is computed based on a predefined expression or from other columns.
Assume you want to retrieve the full name of the person from the following table users directly. What will you do?
You can do this by joining the first_name and last_name with a space following SQL query in the following query
This will give you the following result
Assume if you want to do this process thousands of times and always need the data you can leverage the virtual columns.
This can be done by generating the virtual columns using the following command.
This command will change the table and add a virtual/generated column to the users table.
What happened in the above command?
Here we are adding a generated column/virtual column by using the command alter table and specifying that the newly added column is of type varchar formed using the CONCATing the first_name and last_name.
Similarly, this method can be used to get the discount prices directly from the payments if the user has the original prices and the offered price by subtracting those values and generating the discount column to have MySQL automatically do those operations for you.
By this time most of you may have figured out what we will be doing to provide indexing the JSON entries. We will be generating virtual columns from the JSON datatypes and index them!
How? It’s a good question!
Indexing JSON columns
What we will be doing is extracting the data from JSON fields and create a generated column from it and index the table on it.
So we will use the table1 for this and try to index it.
We will use the following command to generate the new column;
What we did in this command is alter the table1 and added a column generated from the id key present from the jdoc column of the table.
Now selecting the values from the table we will get the following
Now we will be indexing the id column.
Voila. we have our index on JSON;
To check the current indexes on the table use the following command.
This will show the result in the following way
Showing you have the correct index.
This concludes our tutorial on how to add an index on JSON values.
Where this can be helpful?
- When storing email addresses and phone numbers for a contact, where storing them as values in a JSON array is much easier to manage than multiple separate tables
- Saving arbitrary key/value user preferences
- Storing configuration data that has no defined schema
Why it’s not viable?
- Complex queries
- If you really want to be able to add as many fields as you want with no limitation (other than an arbitrary document size limit), consider a NoSQL solution such as MongoDB.
Problems with applying indexes on JSON values
Like everything in life, there is no free lunch. This thing also has some cost/problems stated below.
- Only secondary indexes can be created on the virtual generated columns. These are referenced as virtual indexes.
- When a secondary index is created on a virtual generated column, generated column values are materialized in the records of the index
- If the index is a covering index (one that includes all the columns retrieved by a query), generated column values are retrieved from materialized values in the index structure instead of computed “on the fly”.
- There are additional write costs to consider when using a secondary index on a virtual column due to computation performed when materializing virtual column values in secondary index records during INSERT and UPDATE operations.
- Even with additional write costs, secondary indexes on virtual columns may be preferable to, generated stored columns, which are materialized in the clustered index, resulting in larger tables that require more disk space and memory.
So, in conclusion, this is a pretty good technique to use JSON data in MySQL if you don’t want to migrate to other NoSQL DBS and Postgres which provide pretty good support for the JSON values. Generated columns are also a great feature to implement automatic generation of columns for easy calculations and small calculations. These columns as result provide a good way to add an index to them.
Источник
Гибкая схема хранения данных в MySQL (JSON)
Александр Рубин работает в компании Percona и не единожды выступал на HighLoad++, знаком участникам как эксперт в MySQL. Логично предположить, что и сегодня речь пойдет про что-то, связанное с MySQL. Это так, но лишь отчасти, потому что еще мы поговорим про интернет вещей. Рассказ будет наполовину развлекательный, особенно первая его часть, в которой посмотрим на девайс, который Александр создал, чтобы собрать урожай абрикосов. Такова уж натура настоящего инженера — хочешь фруктов, а покупаешь плату.

Предыстория
Началось все с простого желания посадить фруктовое дерево на своем участке. Сделать это, казалось бы, очень просто — приходишь в магазин и покупаешь саженец. Но в Америке первый вопрос, который задают продавцы, это сколько дерево получит солнечного света. Для Александра это оказалось гигантской загадкой — совершенно неизвестно, сколько солнечного света на участке.
Чтобы это узнать, школьник мог бы каждый день выходить во двор, смотреть, сколько солнечного света, и записывать это в блокнотик. Но это не дело — надо все оснастить оборудованием и автоматизировать.
В ходе выступления многие примеры запускались и воспроизводились в прямом эфире. Хотите более полную картину, чем в тексте, переключайтесь на просмотр видео.
Итак, чтобы не записывать наблюдения о погоде в блокнотик, есть большое количество устройств для интернет-вещей — Raspberry Pi, новый Raspberry Pi, Arduino — тысячи разных платформ. Но я выбрал для этого проекта устройство, которое называется Particle Photon. Оно очень просто в использовании, стоит 19 $ на официальном сайте.
В Particle Photon хорошо то, что это:
- 100% облачное решение;
- подходят любые датчики, например, для Arduino. Они все стоят меньше доллара.
Я сделал такой девайс и положил его в траву на участке. В нем есть Particle Device Cloud и консоль. Этот приборчик подключается через Wi-Fi hotspot и посылает данные: освещенность, температуру и влажность. Приборчик продержался 24 часа на маленькой батарейке, что достаточно неплохо.
Дальше мне нужно не только измерять освещенность и прочее и передавать их на телефон (что на самом деле хорошо — я могу в режиме реального времени видеть, какая у меня освещенность), но и хранить данные. Для этого, естественно, как ветеран MySQL, я выбрал MySQL.
Как мы записываем данные в MySQL
Я выбрал достаточно сложную схему:
- получаю данные из Particle-консоли;
- использую Node.js, чтобы записать их в MySQL.
Я использую Particle API JS, который можно скачать с сайта Particle. Устанавливаю соединение с MySQL и записываю, то есть просто делаю INSERT INTO values. Такой вот pipeline.
Таким образом, девайс лежит во дворе, подсоединяется по Wi-Fi к домашнему роутеру и с помощью протокола MQTT передает данные в Particle. Дальше та самая схема: на виртуальной машине работает программка на Node.js, которая получает данные от Particle и записывает их в MySQL.
Для начала я построил графики из сырых данных в R. На графиках видно, что температура и освещенность днем поднимаются, к ночи падают, а влажность повышается — это естественно. Но также на графике есть шум, это типично для приборов интернета вещей. Например, когда на устройство залез жучок и закрыл его, датчик может передать совершенно нерелевантные данные. Это будет важно при дальнейшем рассмотрении.
Сейчас поговорим про MySQL и JSON, что изменилось в работе с JSON с MySQL 5.7 в MySQL 8. Потом я покажу демо, для которого использую MySQL 8 (на момент доклада эта версия еще не была готова для продакшена, сейчас уже выпущен стабильный релиз).
Хранение данных в MySQL
Когда мы пытаемся хранить данные, полученные с датчиков, наша первая мысль — создать таблицу в MySQL:
Здесь для каждого датчика и для каждого типа данных есть своя колонка: light, temperature, humidity.
Это достаточно логично, но есть проблема — это не гибко. Допустим, мы захотим добавить еще один датчик и измерять что-то еще. Например, некоторые люди измеряют остаток пива в кеге. Что делать в этом случае?
Как извратиться, чтобы в таблицу что-то добавить? Нужно сделать alter table, но если вы делали alter table в MySQL, то знаете, о чем я говорю, — это совершенно непросто. Alter table в MySQL 8 и в MariaDB реализовано намного проще, но исторически это большая проблема. Так что если нам нужно добавить колонку, например, с названием пива, то это будет не так-то просто.
Опять же датчики появляются, исчезают, что нам делать со старыми данными? Например, мы прекращаем получать информацию про освещенность. Или мы создаем новую колонку — как хранить то, чего там до этого не было? Стандартный подход — это null, но для анализа это будет не очень удобно.
Еще один вариант — это key/value store.
Хранение данных в MySQL: key/value
Это будет более гибко: в key/value будет название, например, temperature и соответственно данные.
В этом случае появляется другая проблема — нет типов. Мы не знаем, что мы храним в поле ‘data’. Нам придётся его объявить полем text. Когда я создаю свой девайс интернета вещей, я знаю, какой там датчик и соответственно тип, но если понадобится хранить в той же таблице еще чьи-то данные, то я не буду знать, какие данные собираются.
Можно хранить много таблиц, но создавать одну целую новую таблицу на каждый датчик — не очень-то хорошо.
Что можно сделать? — Использовать JSON.
Хранение данных в MySQL: JSON
Хорошая новость в том, что в MySQL 5.7 можно хранить JSON как поле.
До того, как появился MySQL 5.7, люди тоже хранили JSON, но как поле text. Поле JSON в MySQL позволяет хранить сам JSON наиболее эффективно. Кроме того, на основе JSON можно создать виртуальные колонки и на их основе индексы.
Единственная небольшая проблема — при хранении таблица возрастет в размере. Но зато мы получаем намного большую гибкость.
Поле JSON лучше для хранения JSON, чем поле text, потому что:
- Предоставляет автоматическую валидация документа. То есть если мы попытаемся туда записать что-то не валидное, выпадет ошибка.
- Это оптимизированный формат хранения. JSON хранится в бинарном формате, что позволяет переходить от одного документа JSON к другому — то, что называется skip.
Чтобы хранить данные в JSON, мы можем просто использовать SQL: сделать INSERT, поместить туда ‘data’ и получить данные с девайса.
Для демонстрации (здесь её начало на видео) примера используется виртуальная машина, в которой есть SQL.

Ниже фрагмент программы.
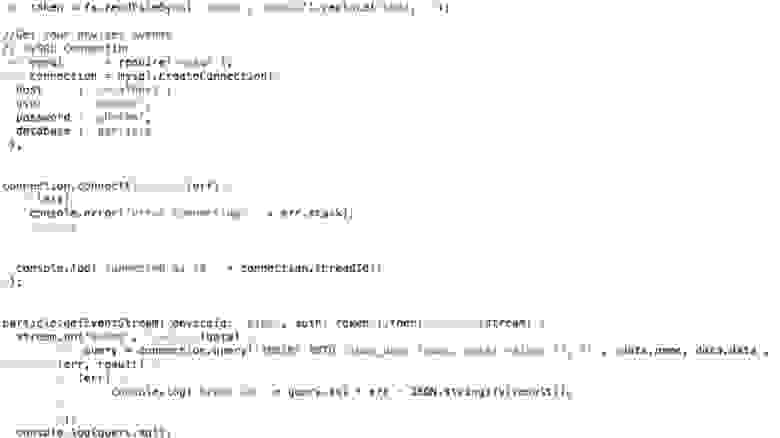
Я делаю INSERT INTO cloud_data (name, data) , получаю данные уже в формате JSON, и могу их прямо записать в MySQL, как есть, совершенно не думая о том, что там внутри.
Как выяснилось, с помощью этого cloud можно получать доступ не только к данным моего устройства, но вообще ко всем данным, которые использует этот самый Particle. Кажется, это работает до сих пор. Люди, которые по всему миру используют Particle Photon, посылают какие-то данные: открыта дверь в гараже, или остаток пива такой-то, или что-то еще. Неизвестно, где эти девайсы находятся, но можно получить такие данные. Разница только в том, что, когда я получаю свои данные, я пишу что-то типа: deviceId: ‘mine’ .
При запуске кода мы получаем поток каких-то данных от чьих-то девайсов, которые что-то делают.

Мы совершенно не знаем, что это за данные: TTL, published_at, coreid, door status (дверь открыта), relay on.
Это прекрасный пример. Допустим, я попытаюсь положить это в MySQL в нормальную структуру данных. Я должен знать, что там за дверь, почему она открыта и какие вообще параметры может принимать. Если у меня есть JSON, то я записываю это прямо в MySQL в виде JSON-поля.

Пожалуйста, все записалось.

Document store
Document store — это попытка в MySQL сделать хранилище для JSON. Я очень люблю SQL, хорошо с ним знаком, могу сделать любой SQL-запрос и т.д. Но многие не любят SQL по разным причинам, и Document store может стать для них решением, потому с его помощью можно абстрагироваться от SQL, подключиться к MySQL и прямо туда записывать JSON. 
Есть еще одна возможность, которая появилась в MySQL 5.7: использовать другой протокол, другой порт, также нужен и другой драйвер. Для Node.js (на самом деле для любых языков программирования — PHP, Java и пр.) мы подключаемся к MySQL по другому протоколу и можем передавать данные в формате JSON. Опять же я не знаю, что у меня в этом JSON — информация про двери или что-то еще, просто данные в MySQL сбрасываю, а что там, разберемся потом.
Если хотите с этим поэкспериментировать, можно сконфигурировать MySQL 5.7 на то, чтобы он понимал и слушал на соответствующем порту Document store или X DevAPI. Я использовал connector-nodejs.
Это пример того, что я туда записываю: пиво и пр. Я совершенно не знаю, что там. Сейчас просто запишем, а проанализируем потом.

Следующий пункт нашей программы — как посмотреть, что там?
Хранение данных в MySQL: JSON + индексы
В JSON и MySQL 5.7 есть отличная функция, которая может вытащить поля из JSON. Это такой синтаксический сахар на функцию JSON_EXTRACT. Мне кажется, это очень удобно.
Data в нашем случае — название колонки, в которой хранится JSON, а name — это наше поле. Name, data, published_at — это все мы таким образом можем вытащить.
В этом примере я хочу посмотреть, что у меня записалось в таблицу MySQL, и 10 последних записей. Я делаю такой запрос и пытаюсь его выполнить. К сожалению, это будет работать очень долго.
Логичным образом MySQL в данном случае не будет использовать никаких индексов. Мы вытаскиваем данные из JSON и пытаемся применить какие-то фильтры и сортировку. В этом случае у нас получится Using filesort.
Using filesort — это очень плохо, это внешняя сортировка.
Хорошая новость в том, что можно сделать 2 шага, чтобы это ускорить.
Шаг 1. Создание виртуальной колонки
Я делаю EXTRACT, то есть вытаскиваю данные из JSON и на его основе создаю виртуальную колонку. Виртуальная колонка в MySQL 5.7 и в MySQL 8 не хранится — это просто возможность создать отдельную колонку.
Вы спросите, как же так, ты же говорил, что ALTER TABLE — это такая долгая операция. Но здесь все не так плохо. Создание виртуальной колонки происходит быстро. Там есть loсk, но на самом деле в MySQL есть lock на всех DDL-операциях. ALTER TABLE — достаточно быстрая операция, и она не перестраивает всю таблицу.
Мы здесь создали виртуальную колонку. Мне пришлось сконвертировать дату, потому что в JSON она хранится в формате iso, а здесь MySQL использует совершенно другой формат. Для создания колонки я назвал ее, дал ей тип и сказал, что буду туда записывать.
Для оптимизации исходного запроса нужно вытащить published_at и name. Published_at уже есть, name проще — просто делаем виртуальную колонку.
Шаг 2. Создание индекса
В коде ниже я создаю индекс на published_at и выполняю запрос:
Видно, что на самом деле MySQL использует индекс. Это оптимизация order by. В данном примере data и name не индексируются. MySQL использует order by data, и так как у нас есть индекс на published_at, то он его и использует.
Более того, я бы мог в order by вместо published_at использовать тот же самый синтаксический сахар STR_TO_DATE(data->>’$.published_at’,»%Y-%m-%dT%T.%fZ») . MySQL бы все равно понял, что есть индекс на эту колонку и начал бы его использовать.
С этим на самом деле есть небольшая проблемка. Допустим, я хочу отсортировать данные не только по published_at, но еще и по названию.
Если ваше устройство обрабатывает десятки тысяч событий в секунду, published_at не даст хорошей сортировки, так как будут дубликаты. Поэтому мы добавляем еще одну сортировку по data_name. Это типичный запрос не только для интернета вещей: дайте мне 10 последних событий, но отсортируйте их по дате, а потом, например, по фамилии человека по возрастанию. Для этого в примере выше есть два поля и указаны два ключа сортировки: descending и ascending.
Прежде всего в этом случае MySQL не будет использовать индексы. В данном конкретном случае MySQL решает, что полный скан таблицы будет выгоднее, чем использование индекса, и опять используется очень медленная операция filesort.
New in MySQL 8.0
descending/ascending
В MySQL 5.7 такой запрос оптимизировать нельзя, если только за счет других вещей. В MySQL 8 появилась реальная возможность указывать сортировку для каждого поля.
Самое интересное, что ключ descending/ascending после названия индекса давно был в SQL. Даже в самой первой версии MySQL 3.23 можно было указать published_at descending или published_at ascending. MySQL это принимал, но ничего не делал, то есть сортировал всегда в одном направлении.
В MySQL 8 это поправили и теперь такая фича есть. Можно создать поле с сортировкой по убыванию и с сортировкой по умолчанию.
Вернемся на секунду назад и посмотрим на пример из шага 2 еще раз.
Почему это работает, а то — нет? Это работает потому, что в MySQL-индексы — это B-tree, а индексы B-tree можно читать и с начала, и с конца. В данном случае MySQL читает индекс с конца и все хорошо. Но если мы делаем descending и ascending, то прочитать нельзя. Можно прочитать в одном порядке, но совместить две сортировки нельзя — нужно пересортировать.
Так как мы оптимизируем совершенно конкретный случай, то можем для него создать индекс и указать конкретную сортировку: здесь published_at — descending, data_name — ascending. MySQL использует этот индекс, и все будет хорошо и быстро.
Это фича MySQL 8, который сейчас, на момент публикации уже доступен и готов для использования в продакшене.
Вывод результатов
Еще есть две интересные штуки, которые я хочу показать:
1. Pretty print, то есть красивый вывод данных на экран. При обычном SELECT JSON будет не форматирован.
2. Можно сказать, чтобы MySQL вывел результат в виде JSON array или JSON object, указать поля, и тогда вывод будет форматирован в виде JSON.
Полнотекстовый поиск внутри документов JSON
Если мы используем гибкую систему хранения и не знаем, что внутри нашего JSON, то было бы логично использовать полнотекстовый поиск.
К сожалению, полнотекстовый поиск имеет свои ограничения. Первое, что я попробовал — это просто создать полнотекстовый ключ. Я попытался сделать такую штуку:
К сожалению, это не работает. Даже в MySQL 8 создать полнотекстовый индекс просто по полю JSON, к сожалению, невозможно. Я бы конечно хотел иметь такую функцию — возможность поиска хотя бы по ключам JSON была бы очень полезна.
Но если это пока невозможно, давайте создадим виртуальную колонку. В нашем случае есть поле data, и нам интересно было бы посмотреть, что там внутри.
К сожалению, это тоже не работает — на виртуальной колонке нельзя создать полнотекстовый индекс.
Раз так, давайте создадим хранимую колонку. MySQL 5.7 позволяет объявить колонку хранимым полем.
В предыдущих примерах мы создавали виртуальные колонки, которые не хранятся, но индексы создаются и хранятся. В данном случае мне пришлось сказать MySQL, что это колонка STORED, то есть она будет создана и данные в нее будут скопированы. После этого MySQL создал полнотекстовый индекс, для этого пришлось пересоздать таблицу. Но это ограничение на самом деле InnoDB и InnoDB fulltext search: приходится пересоздавать таблицу, чтобы добавить специальный идентификатор полнотекстового поиска.
Интересно, что в MySQL 8 появилась новая кодировка UTF8MB4 для смайликов. Конечно, не совсем для них, а потому что в UTF8MB3 есть некоторые проблемы с русским, китайским, японским и другими языками.
Соответственно MySQL 8 должен хранить данные JSON в UTF8MB4. Но то ли из-за того, что Node.js коннектится к Device Cloud, и там записано что-то не так, или это баг бета-версии, этого не произошло. Поэтому мне пришлось сконвертировать данные, перед тем как записать их в хранимую колонку.
После этого я смог создать полнотекстовый поиск на двух полях: на названии JSON и на данных JSON.
Not only IoT
JSON — это не только интернет вещей. Он может использоваться для других интересных штук:
- Custom fields (CMS);
- Complex structures и т.д.;
Некоторые вещи могут быть намного удобнее реализованы с помощью гибкой схемы хранения данных. На Oracle OpenWorld приводился отличный пример: резервирование мест в кинотеатре. Реализовать это в реляционной модели очень сложно — получается много зависимых таблиц, джойнов и т.д. С другой стороны, мы можем хранить весь зал как структуру JSON, соответственно, записывать его в MySQL в другие таблицы и использовать обычным образом: создать индексы на основе JSON и т.д. Сложные структуры удобно хранить в формате JSON.

Это дерево, которое было успешно посажено. К сожалению, через несколько лет его съели олени, но это уже совсем другая история.
Этот доклад — отличный пример того, как из одной темы на большой конференции, вырастает целая секция, а потом и обособленное отдельное мероприятие. В случае интернета вещей у нас получилась InoThings++ — конференция для профессионалов рынка интернета вещей, которая 4 апреля пройдет уже во второй раз.
Центральным событием конференции, похоже, станет круглый стол «Нужны ли нам национальные стандарты в Интернете Вещей?», который органично дополнят всесторонние прикладные доклады. Приходите, если и ваши высоконагруженные системы верно двигаются к IIoT.
Источник